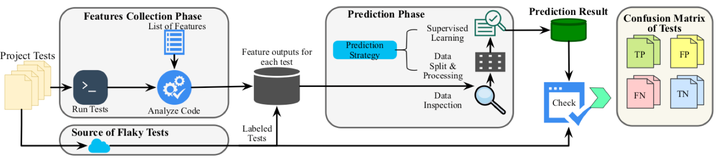
Abstract
When developers make changes to their code, they typically run regression tests to detect if their recent changes (re)introduce any bugs. However, many tests are flaky, and their outcomes can change non-deterministically, failing without apparent cause. Flaky tests are a significant nuisance in the development process, since they make it more difficult for developers to trust the outcome of their tests, and hence, it is important to know which tests are flaky. The traditional approach to identify flaky tests is to rerun them multiple times: if a test is observed both passing and failing on the same code, it is definitely flaky. We conducted a very large empirical study looking for flaky tests by rerunning the test suites of 24 projects 10,000 times each, and found that even with this many reruns, some previously identified flaky tests were still not detected. We propose FlakeFlagger, a novel approach that collects a set of features describing the behavior of each test, and then predicts tests that are likely to be flaky based on similar behavioral features. We found that FlakeFlagger correctly labeled as flaky at least as many tests as a state-of-the-art flaky test classifier, but that FlakeFlagger reported far fewer false positives. This lower false positive rate translates directly to saved time for researchers and developers who use the classification result to guide more expensive flaky test detection processes. Evaluated on our dataset of 23 projects with flaky tests, FlakeFlagger outperformed the prior approach (by F1 score) on 16 projects and tied on 4 projects. Our results indicate that this approach can be effective for identifying likely flaky tests prior to running time-consuming flaky test detectors.